
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 데이터자격증
- 우금캐
- boostcourse
- 데이터리안
- 데이터분석마인드셋
- 정처기
- 데이터분석
- 실기1유형
- 빅데이터분석기사실기
- 통계독학
- 투자마인드
- 빅분기1유형
- sql
- 우금캐면접
- 메타코드m
- 메타코드
- 데이터분석가
- 컨버티드
- 빅분기 실기
- 빅분기
- MySQL
- 빅분기실기
- 우리금융캐피탈
- BNK저축은행
- 데이터분석전문가
- 빅데이터분석기사
- 우리금융캐피탈면접
- 빅데이터분석기사 실기
- 데이터넥스트레벨챌린지
- 투자도서
- Today
- Total
하파와 데이터
의사결정나무 쉽게 따라해보기!(plot_tree그리기, 중요 feature 파악하기) 본문
머신러닝에서 많이 사용되는 방법 중 '의사결정나무'가 있다.
의사결정 나무의 장점으로는 어떤 기준으로 분류를 하는지 명확하게 확인할 수 있다는 것이다.
이에 의사결정나무(DecisionTree)를 그려보는 것을 간단히 해보고자 한다.
본 연습은 naver connect재단에서 운영하는 boostcourse 강의 중
오늘 코딩 '박조은'님의 '프로젝트로 배우는 데이터사이언스'에서 학습한 내용을 토대로 한다.
아래의 실습을 따라하면, 간단하게 머신러닝을 실습해볼 수 있다.
활용데이터: Pima Indians Diabetes (출처: https://www.kaggle.com/datasets/uciml/pima-indians-diabetes-database)
환경: jupyter notebook
1. 데이터 구성확인
데이터 columns이 어떤 것으로 구성되어있는지, 각 컬럼의 의미는 무엇인지 파악하는게 필요하다.
- Pregnancies: 임신 횟수
- Glucose: 2시간 동안 경구 포도당 내성 검사에서 혈장 포도당 농도
- BloodPressure: 이완기 혈압(mm Hg)
- SkinThckness:삼두근 피부 주름 두께(mm), 체지방을 추정하는데 사용되는 값
- Insulin: 2시간 혈청 인슐링(mu U/ml)
- BMI:체질량 지수(weight / height^2)
- DiabetesPedigressFunction:당노병 혈통 기능
- Age:나이
- Outcome: 768개 중 268개결과 클래스가 1(당뇨병)이고 나머지는 0(당뇨병x)
2. 필요한 라이브러리 로드
이번 데이터 분석에 필요한 모든 라이브러리를 import
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
3. 데이터셋 로드
kaggle에서 다운받은 csv파일을 jupyter notebook의 시작 위치 내에 있는 'data' 폴더에 저장해두었다.
저장된 파일이 다른 경로에 있는 경우, 'data/diabetes.csv'의 부분을 파일 위치에 맞게 수정해야한다.
df = pd.read_csv('data/diabetes.csv')
4. 데이터 확인
데이터의 형태, 구조 등을 확인한다.
df.shape #(768, 9)
df.head()
df.info() # 모두 숫자형(int64, float64)이며, 결측값은 없음
# 전처리가 필요하지 않은 상황
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 768 entries, 0 to 767
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Pregnancies 768 non-null int64
1 Glucose 768 non-null int64
2 BloodPressure 768 non-null int64
3 SkinThickness 768 non-null int64
4 Insulin 768 non-null int64
5 BMI 768 non-null float64
6 DiabetesPedigreeFunction 768 non-null float64
7 Age 768 non-null int64
8 Outcome 768 non-null int64
dtypes: float64(2), int64(7)
memory usage: 54.1 KB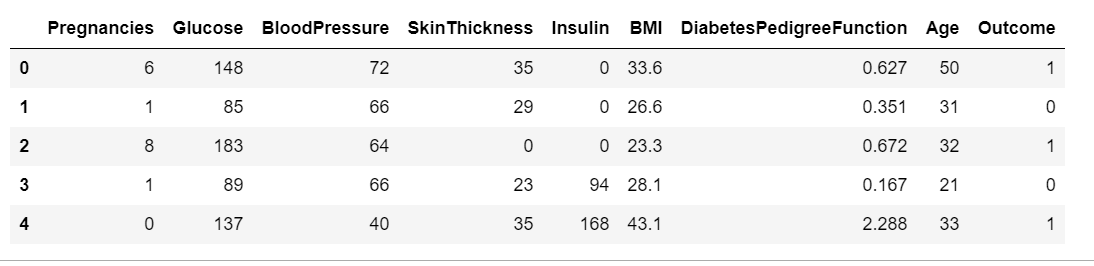
5. 학습, 예측 데이터셋 나누기
sklearn.model_selection.train_test_split을 활용하면 쉽게 나눌 수 있지만,
여기서는 비율을 지정하여, 나누는 동작 원리를 알아보기 위해 직접 나누는 과정을
하드코딩으로 실행해보고자 한다.
# hold-out을 진행하고자 하며, 비율은 8:2로 예정
# 전체 데이터 행에서 80%위치에 해당하는 값을 구해 split_count변수에 담기
split_count = int(df.shape[0] * 0.8)
split_count # 614
# train, test로 데이터 슬리이싱을 통해 데이터 분할
train = df[:split_count].copy() # 0~613번 인덱스까지의 데이터를 포함, 전체의 80%, .copy()를 통해 깊은 복사
test = df[split_count:].copy() # 614번 인덱스부터 끝까지 데이터를 포함, 전체의 20% , .copy()를 통해 깊은 복사
train.shape # (614, 9)
test.shape #(154, 9)
6. 종속, 독립변수 컬럼 구분
현재 train, test 데이터에는 종속변수(dependent variable )와 독립변수(independent variable )가 하나의 df에 포함되어있다. 이 형태로는 머신러닝으로 학습을 시킬 수 없으니, feature인 독립변수와 그에 따른 결과값인 종속변수를 나누어 본다.
# feature_names에 독립변수 컬럼명을 저장
feature_names = train.columns[:-1].to_list()
feature_names # 독립변수만 저장됨
# feature 가 list로 저장됨
['Pregnancies',
'Glucose',
'BloodPressure',
'SkinThickness',
'Insulin',
'BMI',
'DiabetesPedigreeFunction',
'Age']
# 종속변수를 label에 저장
label = train.columns[-1]
label
7. 학습, 예측 데이터셋 만들기
앞서 만들어둔 X와 y 데이터프레임은 독립변수와 종속변수의 구분없이 모두가 들어있다.
이에, 앞서 독립, 종속변수의 컬럼명 지정한 내용을 참고하여, 데이터셋을 만들어본다.
# train set 만들기
X_train = train[feature_names] # 독립변수만 표현됨
X_train.shape #(614, 8)
X_train.head()
# y_train set 만들기
y_train = train[label]
y_train.shape # (614,) # X와 y의 데이터 행의 수가 같아야함!
y_train.head()
# 예측에 사용할 test 데이터의 종속변수, 독립변수를 구분
X_test = test[feature_names]
y_test = test[label]
print(X_test.shape) # (154, 8) # coulmns수가 앞선 X_train의 columns수와 동일해야함
print(X_test.head())
print(y_test.shape) # (154, ) # row가 X_test와 같아야함
print(y_test.head())
8. 머신런닝 알고리즘 가져오기
지도학습 중 분류를 하는 분류의사결정나무를 사용한다.
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model
9. 학습(훈련) 및 예측
앞서 처리해둔 Train데이터를 활용해 모델을 학습시키고, test데이터를 활용해 예측 결과를 확인
# 모델 학습
model = model.fit(X_train, y_train)
# 모델 예측
y_predict = model.predict(X_test)
y_predict[:5]
10. 의사결정나무 알고리즘 분석하기
plot_tree를 그려봄으로 어떤 기준으로 분류가 이루어졌는지 확인해본다.
# 알고리즘 그림을 위한 plot_tree import
from sklearn.tree import plot_tree
plt.figure(figsize=(20,20))
tree = plot_tree(model,
feature_names = feature_names,
max_depth=5, # 그림이 너무 길어지지 않도록 max_depth를 제한
filled = True,
fontsize = 10)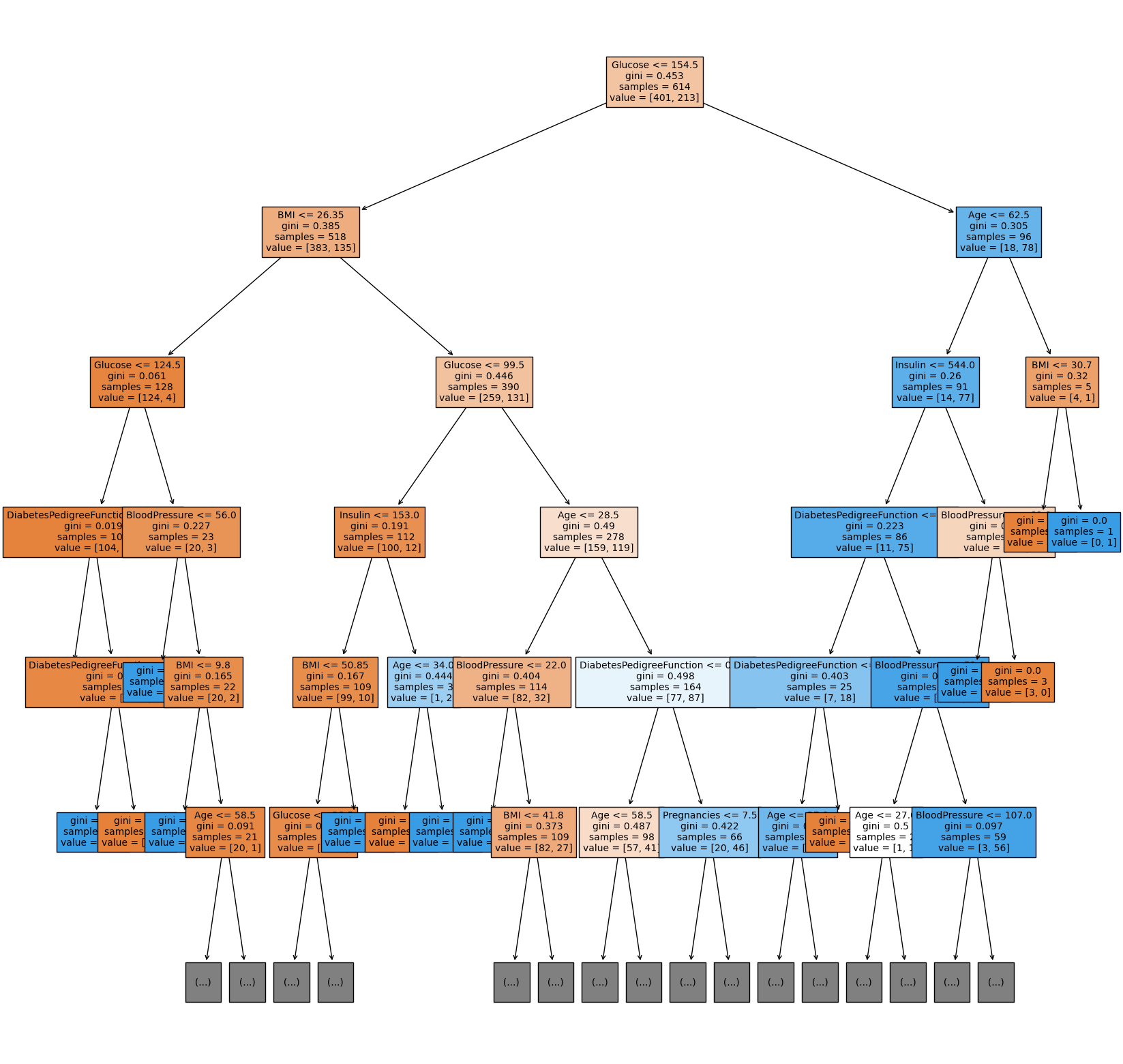
첫번째 구분점의 기준이 Glucose라는 것을 확인할 수 있다.
이외에는 어떤 feature들이 중요도를 갖는지도 확인해본다.
# feature 중요도 추출하기
model.feature_importances_
# feature importance로 그래프 그리기
sns.barplot(x = model.feature_importances_, y = feature_names)
11. 정확도 측정하기
정확도를 측정하는 방법은 다양하다.
모듈을 임포트해서 리포트를 만들고 다양한 지표도 함께 볼 수 있지만,
여기서는 어떤 방식으로 정확도를 측정하는 것인지 원리를 보면서 측정해보고자 한다.
# 예측값이 실제값과 동일한 결과가 나왔다면, 실제값 - 예측값을 빼주면 0으로 나옴
# 예측결과가 실제와 일치하지 않을 경우, 1 또는 -1이 나옴(1,0) 또는 (0,1)이기 때문에
# 이에 (실제값 - 예측값)을 확인하여 예측의 성패 여부를 확인함
# 둘의 차리에 절대값을 씌운 값이 1인 값이 나오면, 다르게 예측한 값이 됨
# 둘의 값을 빼서 절대값을 씌우고 그것들을 모두 더하고, 그 결과들을 다 sum
diff_count = abs(y_test - y_predict).sum()
diff_count
# 정확도 구하기
acc = ((len(y_test)-diff_count) / len(y_test))*100 # 70.78%
이런 방법 외에도 정확도를 확인할 수 있는 2가지 방법이 있다.
# sklearn 모듈 이용해서 정확도 측정하기
from sklearn.metrics import accuracy_score
acc = accuracy_score(y_test, y_predict) * 100
acc
# model에서 score 바로 계산하기
model.score(X_test, y_test)
여기서 언급된 3가지의 정확도 측정의 결과는 모두 동일하게 나온다.
짧지만, 이 과정까지 진행해본다면
간단히 데이터를 처리하고, 분할한뒤
머신러닝 모델에 학습, 예측
알고리즘 분석 및 정확도 측정까지 해볼 수 있다.
'Development > Python' 카테고리의 다른 글
| df.describe(include='object') 데이터프레임 기술분석 다양하게 해보기 (1) | 2024.01.15 |
|---|---|
| return으로 데이터 바로 분할하기(return_X_y=True) (0) | 2024.01.12 |
| Python 자료형 - 자료형과 자료형 확인하는 법 (0) | 2023.07.20 |


