
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 컨버티드
- 빅데이터분석기사 실기
- 빅분기실기
- 투자마인드
- 통계독학
- 우금캐면접
- 실기1유형
- 데이터분석전문가
- 빅분기 실기
- sql
- 데이터분석
- 데이터넥스트레벨챌린지
- 정처기
- 데이터분석마인드셋
- BNK저축은행
- 투자도서
- 데이터분석가
- 빅분기
- 메타코드
- 우리금융캐피탈
- 우금캐
- 빅데이터분석기사실기
- 메타코드m
- 데이터리안
- 빅분기1유형
- MySQL
- 빅데이터분석기사
- 데이터자격증
- 우리금융캐피탈면접
- boostcourse
- Today
- Total
하파와 데이터
[딥러닝전문가과정] Course1. NN and DL- Introduction 본문
AI는 사회의 새로운 원천으로 작용하고 있다. 사회를 변화시키고, 사회는 AI를 통해서 많은 것들을 얻게 된다.
80년대 컴퓨터의 기술이 발전되지 못했고, 다양한 데이터도 없었으며, 인공지능 관련 학문의 발전도 빈약했던 시기와 다르게 요즘은 많은 기술과 데이터의 발생으로 지금까지와는 너무 다른 세상을 보여주고 있다.
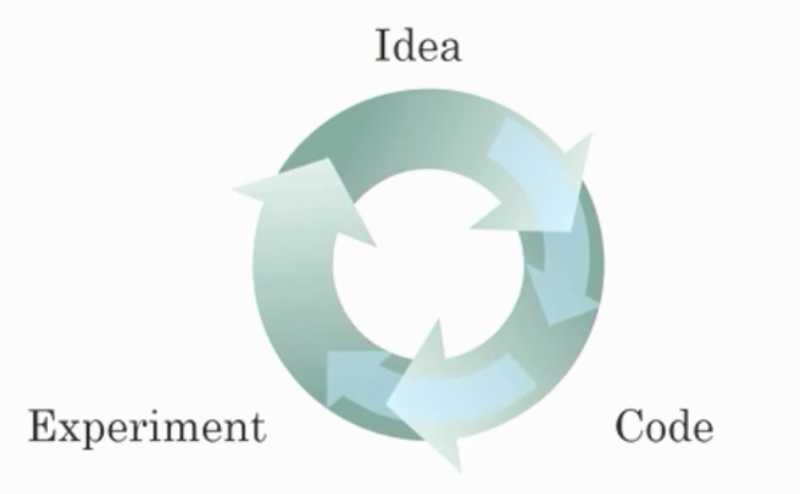
특히 이러한 변화는 위의 그림에서 혁신을 일으켰다. 예전에는 아이디어를 구상하고 코드를 작성하는데 많은 시간이 소요되었다. 하드웨어적으로 어려웠다. 그리고 Experiment로 나아갈 때에도 어려움이 많았다. 다시 idea부분에서도 많은 데이터가 없고 활용도가 없으니 아이디어도 충분하지 않았다.
하지만 컴퓨터의 발전으로 코드로 구현하고, 빠르게 시도해보는 일들이 가능하게 되었다. 이로써 전체의 과정이 훨씬 빠르고 민첩하게 움직이기 시작했다.
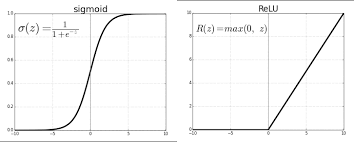
알고리즘의 기술적인 부분에서는 ReLU함수의 출현으로 많은 발전을 다가오게 해주었다. 기존까지의 sigmoid함수의 경우, 기울기가 0이 되는 부분이 많이 발생했으나, ReLU함수를 이용할 경우, 0보다 클때는 미분시 0을 갖는 값이 없도록 나온다.
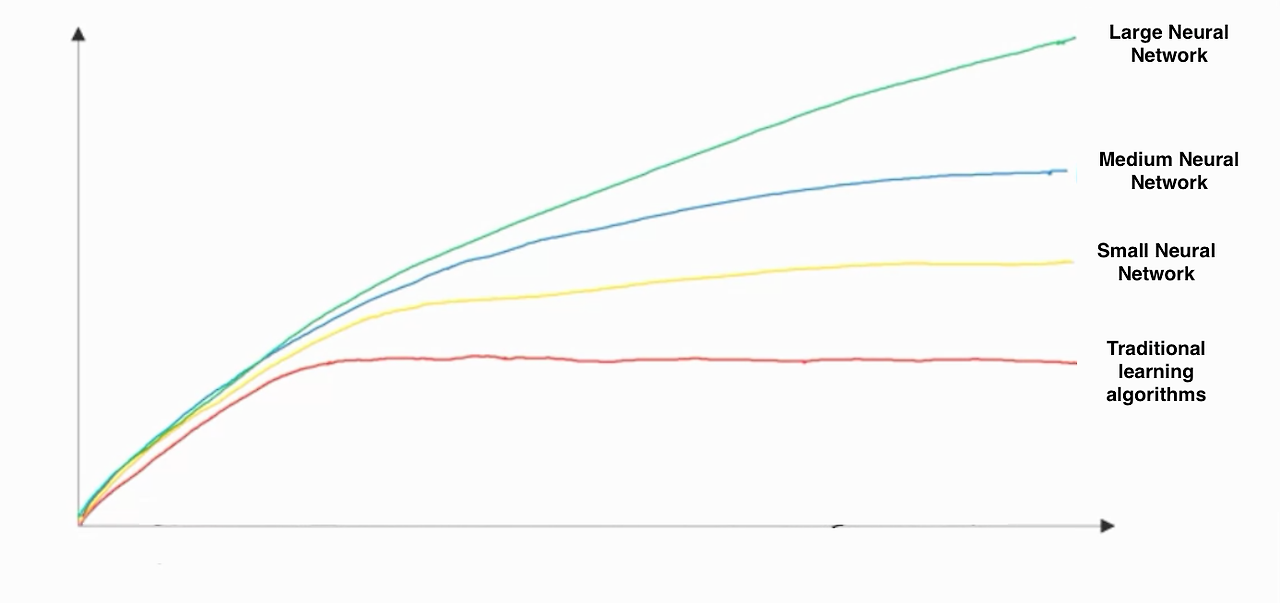
위의 그래프는 X축에는 데이터의 양, 그리고 Y축에는 성능을 둔 그래프이다. 교수님께서 손으로 그린 저 그래프가 대략적이지만, 정확하다고 가정하고 그래프를 본다면 데이터 양이 일정 이상으로 크지 않다면, 기존의 알고리즘과 거대NN의 성능 차이는 존재하지 않게 된다.
즉, NN의 성능이 좋기 위해선 많은 양의 데이터가 필요하다. 그리고 데이터의 양이 많지 않은 상황이라면 굳이 LNN과 같은 많은 연산처리를 하는 과정을 수행하기보다는 전통적인 학습 알고리즘을 활용하여 결과를 도출하는 것이 합리적이다.
많은 연산을 하는 작업이 항상 좋은 것은 아니다.
'스터디 > 캐글코리아-딥러닝기본기' 카테고리의 다른 글
| 새로운 스터디의 시작- 캐글코리아 딥러닝스터디 (4) | 2024.01.26 |
|---|
