
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 데이터분석
- 메타코드m
- 빅데이터분석기사 실기
- 메타코드
- MySQL
- boostcourse
- 데이터분석전문가
- 투자도서
- 빅데이터분석기사
- 통계독학
- 우리금융캐피탈
- 우리금융캐피탈면접
- 우금캐
- 실기1유형
- 빅분기1유형
- 데이터분석가
- 데이터리안
- 빅분기 실기
- BNK저축은행
- 데이터넥스트레벨챌린지
- sql
- 빅분기
- 빅데이터분석기사실기
- 데이터자격증
- 빅분기실기
- 투자마인드
- 정처기
- 컨버티드
- 우금캐면접
- 데이터분석마인드셋
- Today
- Total
하파와 데이터
[빅분기] 실기 1유형- 결측치, 중복 제거(nan, duplicates) 본문
데이터에서 가장 큰 골치거리가 결측지다.
하나만 비어있을때는 전체를 날리지도 못하고,
너무 무의미한 데이터가 많다면, 결측치가 많은 컬럼 자체를 날려야하는 경우도 있다.
즉, 우리의 필요에 따라서 우리는 결측된 데이터들을 제거하거나, 보완하는 방법을 알아야 한다.
우리는 그중에서 우선 간단한 방법인 평균으로 결측을 보완하는 방법과
아예 결측치를 제거하는 방법에 대해서 알아본다.
나아가, 유니크한 값을 구하는 다른 방법인 중복값들을 제거하는 방법도 배워본다!
0. 전제
우리만의 DataFrame을 만든다.
import pandas as pd
import numpy as np
dates = pd.date_range('20241129', periods= 6)
df = pd.DataFrame(np.random.randn(6,4), index = dates, columns = list('ABCD'))
df
1. 결측치 보완
우선, 현재 데이터에서 결측을 만든 뒤, 평균 값을 구하여 그 값으로 결측치들을 채워보자.
df1 = df.copy()
# A 컬럼 데이터를 3개 아래로 내림
df1['A'] = df1['A'].shift(3)
print(df1)
# 데이터의 평균 값으로 결측치 채우기
df1['A'] = df1.fillna(df1['A'].mean())
print(df1)
df['A']의 평균은 -0.922154였음을 알 수 있다.
2. 결측치 제거, dropna()
지금은 결측치를 평균으로 보완해보았다.
근데, 이미 나에게 충분한 데이터가 있다는 가정을 할때,
그리고 결측이 1개 또는 2개라면 내가 데이터의 결측을 임의로 채우기보단
결측의 데이터를 제거하는게 더 완성도를 높일 수 있다.
그러니, 결측을 제거하는 것도 배워보자. 이것도 쉽다 .
df2 = df.copy()
# A 컬럼의 3개 행을 아래로 내림
df2['A'] = df2['A'].shift(3)
# A컬럼에서 결측지를 제거함
df2 = df2.dropna(subset = ['A'])
#df2.dropna(subset = ['A'], inplace = True)
df2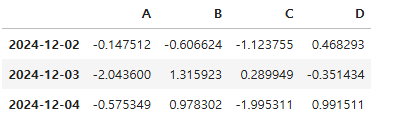
결측을 갖던 20241129 ~ 20241201의 데이터가 제거된 것을 확인할 수 있다.
3. 중복 제거.
중복 제거는 사실 어떤 이유에서 실제 사용하는지 아직은 감이 없다.
우선, unique와 유사한 의미로 이해하고 있다.
우선 unique로 고유값들이 무엇인지 확인한다.
여기는 iris.csv파일로 데이터를 다뤄보자
import pandas as pd
df = pd.read_csv('data/iris.csv')
df['variety'].unique()
이미 알고 있든, 3가지 종류가 있음을 확인할 수 있다.
그렇다면, 각각 50개씩의 데이터 가운데, 중복을 제거하고 품종별 1개의 데이터만을 갖고싶다면?
자 해보자
import pandas as pd
df = pd.read_csv('data/iris.csv')
df.drop_duplicates(subset=['variety'], inplace = True)
df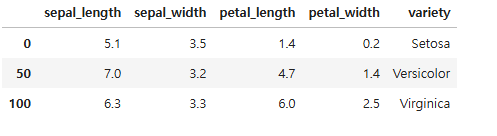
drop_duplicates()를 실행하면, 각 품종별 첫번째 데이터만 남기고 중복되는 나머지들을 다 삭제해버린다.
흠. 이걸 어디 쓸런지...
'자격증 > DATA' 카테고리의 다른 글
| [정처기] 비전공자를 위한 5일 정처기 강의(1주차); SW설계 (4) | 2024.12.09 |
|---|---|
| [빅분기] 실기 1유형- 데이터 처리 실습해보기! (0) | 2024.11.29 |
| [빅분기] 실기 1유형- 인코딩(Encoding), Categorical().codes, get_dummies() (1) | 2024.11.29 |
| [빅분기] 실기 1유형- 데이터 정렬(sorting) (1) | 2024.11.29 |
| [빅분기] 실기 1유형- 인덱스(Index) 설정, 리셋, 정렬 (1) | 2024.11.29 |



