
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 우금캐면접
- 메타코드m
- 우리금융캐피탈면접
- 투자마인드
- sql
- 데이터분석전문가
- MySQL
- 메타코드
- BNK저축은행
- 데이터분석
- 빅데이터분석기사 실기
- 실기1유형
- 데이터분석가
- 빅분기 실기
- 우금캐
- 빅분기
- 데이터분석마인드셋
- 빅분기1유형
- 통계독학
- 빅데이터분석기사
- 데이터넥스트레벨챌린지
- 빅데이터분석기사실기
- boostcourse
- 데이터리안
- 데이터자격증
- 우리금융캐피탈
- 투자도서
- 정처기
- 빅분기실기
- 컨버티드
- Today
- Total
하파와 데이터
[빅분기] 실기 1유형- 읽기, 쓰기, Transpose 본문
이번주 토요일 오전 10시, 나는 빅데이터분석기사 실기를 보러간다.
우선 현재 상태는,
오랜만에 Jupyter notebook을 켰고,
Pandas의 기본 문법을 사용한지도 오래되어서,
기본적인 메소드도 잊어버린게 많다.
그래서 유데미를 통해 빅분기 실기 강의를 들으면서,
거기서 배운 내용을 간략하게 정리하고자 한다.
스스로에게는 복습을 하며 기억을 하는 것으로,
이 글을 보는 빅분기 실기 준비생에게는 어떤 것을 준비해야하는지 알아야 하는 글로 이해가 되면 좋겠다.
우선 내가 듣는 강의는
udemy에서 이래중 박사(Ph.D)님의 빅분기 강의다.
https://www.udemy.com/course/rfjhluyv/
나는 유데미 계정이 있어서, 들을 수 있는데,
현재 강의를 보면서 느끼는 것은 굳.....이 돈내가면서 강의를 듣고
시험을 준비할 필요까지는 없을 것 같다.
여러 블로그와 다양한 채널을 통해서 실기를 준비할 수 있을 것 같기도 하다.
대학이나, 여러 루트를 통해서 무료강의를 들을수 있다면
가장 좋겠지만, 그렇지 않더라도 빅분기 실기가 엄청난걸 요구하는 것 같지는 않으니!!
이에 나는 박사님께서 알려주시는 '빅분기 실기'에 필요한 여러가지들을 여기에 적어보고자 한다.
코드를 적으려고 해도, 무언가 상황이 있어야 하니,
전제는 jupyter notebook을 연 폴더 내 data라는 폴더가 있고, 그 안에 iris.csv라는 파일이 있다고 가정을 하고 아래 코드를 작성한다.
1. CSV 읽어오기
import pandas as pd
df = pd.read_csv('data/iris.csv')
df.head()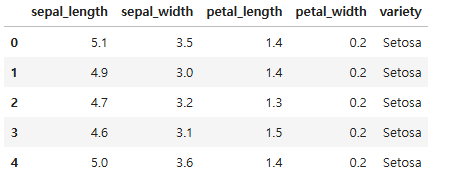
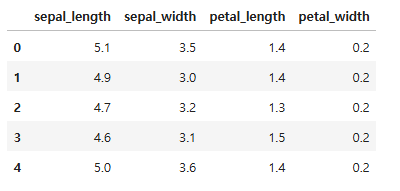
2. CSV 저장하기(쓰기)
만일 내가 전처리를 하고, 이래저래 다 만진 데이터를 최종으로 확정하고, csv파일로 저장을 하고 싶다면?
import pandas as pd
df = pd.read_csv('data/iris.csv')
# variety 컬럼 삭제
df.drop('variety', axis=1, inplace = True)
# 삭제 여부 확인
df.head()
# variety 컬럼을 삭제한 df를 new_iris.csv로 저장
df.to_csv('data/new_iris.csv', index = False)저장할때, 중요한건 index = False라는 것!!
3. DF.T(Transpose) 전치하기
Transpose는 우리말로 '전치'라고 하며, 행과 열을 뒤바꾸는 작업을 수행한다. (n,m) -> (m,n)
그리고 방법도 아주 쉽다. 데이터 프레임에 .T 이렇게 대문자 T만 넣으면 바로 해준다. (고놈 참 쉽구먼)
아직은 많은 데이터를 다루고 특별히 전치를 마주해본적이 없어서 실 활용도는 얼마일지는 모르겠으나,
나중에 데이터 볼때 필요한 순간이 있겠지...
import pandas as pd
import numpy as np
# (3,5) 형태의 DataFrame 생성
dates = pd.date_range('20241126', periods = 3)
df = pd.DataFrame(np.random.randint(1,100,(3,5)), index = dates, columns = list('ABCDE'))
# df 출력
df
# 전치(Transpose)
df2 = df.T
df2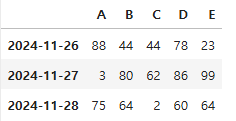
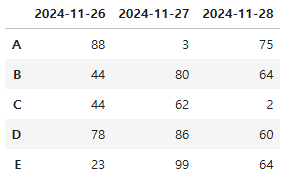
'자격증 > DATA' 카테고리의 다른 글
| [빅분기] 실기 1유형- 데이터 선택; 부분집합(SUBSET) (0) | 2024.11.27 |
|---|---|
| [빅분기] 실기 1유형- 상관계수 (1) | 2024.11.27 |
| [빅분기] 실기 1유형- 수치형 데이터 분석(개수, 최소, 최대, 평균, 합계, 중앙값, 4분위, 분산, 표준편차,왜도, 첨도) (1) | 2024.11.27 |
| [빅분기] 실기 1유형- 결측치 찾기, 고유값 확인, 값 개수 찾기 (1) | 2024.11.27 |
| [정처기] 메타코드 강의를 통한 필기 준비! (0) | 2024.11.22 |



