
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 통계독학
- 메타코드m
- 우금캐면접
- 빅데이터분석기사실기
- 컨버티드
- 데이터넥스트레벨챌린지
- MySQL
- 빅분기 실기
- boostcourse
- 정처기
- 데이터분석가
- 투자마인드
- 데이터분석
- 빅데이터분석기사
- 우리금융캐피탈
- 빅데이터분석기사 실기
- BNK저축은행
- 실기1유형
- 데이터자격증
- sql
- 빅분기
- 데이터분석전문가
- 투자도서
- 빅분기실기
- 데이터분석마인드셋
- 우금캐
- 메타코드
- 데이터리안
- 우리금융캐피탈면접
- 빅분기1유형
- Today
- Total
하파와 데이터
1. EDA-1 본문
이 프로젝트의 경우, 다양한 모델을 만들어서,
개인 맞춤형 추천 서비스를 구축하는 것이 목표다 .
우선 데이터셋은 캐글에 있는 데이터를 원 파일로 하지만,
기본 데이터에서 이미지, 의미없는 컬럼들을 삭제한 채 시작한다.
덧붙여, 캐글 노트북을 이용할 수 있지만,
나는 그냥 VS CODE를 이용해서 작업을 수행하였다.
기본 소스파일 출처 : https://www.kaggle.com/datasets/arashnic/book-recommendation-dataset/data
Book Recommendation Dataset
Build state-of-the-art models for book recommendation system
www.kaggle.com
0. 준비단계
가장 앞서, 필요한 라이브러리들을 호출하고, 준비 과정을 거친다.
# pre setting
import warnings
warnings.filterwarnings(action = 'ignore')
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
pd.set_option('display.max_colwidth', None)
sns.set(style = "whitegrid")
from IPython.display import Image, display
file_name = 'books.csv'
나는 데이터가 담긴 csv 파일을 vs code 오픈 위치와 동일한 곳에 두어서
pd.read_csv에서 위치 지정이 따로 필요하지 않아. data_path를 설정하지 않았다.
1. 파일 읽기
# read the file
df = pd.read_csv(file_name)
df.head()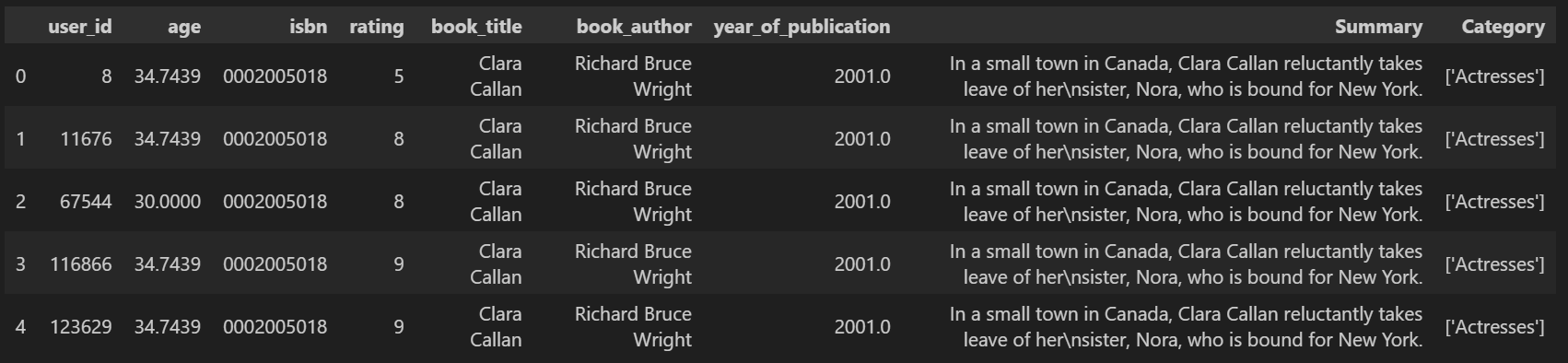
df.head()를 통해 5개의 행을 살펴볼 수 있다.
2. 데이터 프레임 점검하기(df.info())
df.info()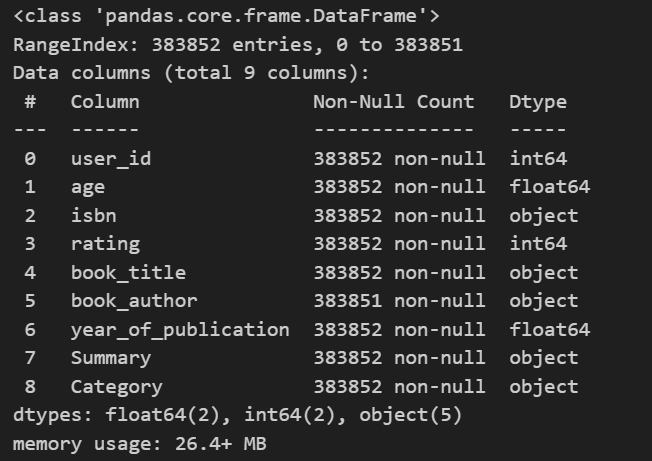
사실 info를 찍으면, 지금까지는 정형적인 데이터들만 봐와서 큰 무리가 없었다.
습관적으로 찍은 info를 보면서, nan의 숫자를 비교하는 것도 중요하지만,
head의 내용을 보면서, dtype이 제대로 구성되어있는지 확인도 필요하다.
날짜인데 datetime으로 변경이 필요한지
숫자인데 object로 되어있는지 등의 확인을 해야, 나중에 분석할 때 효율적으로 업무를 수행할 수 있다.
현재 info를 기준으로 봤을대, 결측이 있는 곳은 book_author로만 보인다.
dtype의 경우는 age가 float으로 처리되었다는 점이 특이하고 이외는 특이점이 없는 것 같다.
3. category, summary 데이터 확인해보기
# check how the category is distributed
print(df.groupby('Category').size().sort_values(ascending = False))
print(df.groupby('Summary').size().sort_values(ascending = False))
# The largest category and summary value is '9'
# '9' represents NaN, which needs to be corrected

카테고리와 summary에서 가장 많은 비중을 차지하고 있는 값은 9이다.
카테고리는 책의 분야를 설명해야하는데 9, summary는 책의 내용을 간략히 설명하는 부분인데, 9
여기서 9가 의미하는 바는 nan과 동일하다. 빈 값을 9로 채워서 있는 형태기 때문에 이를 우리는 처리해야한다.
4. 데이터 전처리
# Preprocessing
df.columns = df.columns.str.lower() # make all column names lowercase
df['rating'] = df['rating'].astype('float')
df['age_range'] = (df['age']/10).astype('int') * 10
df['category'] = df['category'].replace('9', np.nan)
df['category'] = df['category'].str.replace('[','').str.replace(']','')
df['summary'] = df['summary'].replace('9',np.nan)
우선 columns을 편하게 사용하기 위해서, 첫글자가 대문자였던 상태에서 모두 소문자로 변경하였다.
그리고 평가점을 int에서 float 형태로 변환하였다.
age는 이해할 수 없는 소수점 형태였기 때문에, 기존 age보단 10대, 20대 등의로 활용하기 위해 age_range 컬럼을 만들어서 추가하였다.
category에는 "[]"가 있었기에, 이를 삭제하는 작업을 수행하였다.
마지막으로 앞서 확인한 바와 같이, category와 summary 컬럼에서 9를 numpy를 활용하여 nan으로 처리하였다.
'스터디 > [메타코드]캐글을 활용한 개인화 추천시스템 실습' 카테고리의 다른 글
| 0. 프로젝트 소개 (1) | 2024.12.13 |
|---|---|
| [시작하며] 메타코드M 캐글을 활용한 개인화 추천시스템 실습 강의 장학생!(딥러닝, 머신러닝) (3) | 2024.12.04 |

